Lecture 26: Clustering and machine learning with scikit-learn¶
CBIO (CSCI) 4835/6835: Introduction to Computational Biology
Overview and Objectives¶
It's nice when you're able to automate a lot of your data analysis. Unfortunately, quite a bit of this analysis is "fuzzy"--it doesn't have well-defined right or wrong answers, but instead relies on sophisticated algorithmic and statistical analyses. Fortunately, a lot of these analyses have been implemented in the scikit-learn Python library. By the end of this lecture, you should be able to:
- Define clustering, the kinds of problems it is designed to solve, and the most popular clustering variants
- Use SciPy to perform hierarchical clustering of expression data
- Define machine learning
- Understand when to use supervised versus unsupervised learning
- Create a basic classifier
Part 1: Clustering¶
What is clustering?
Wikipedia:
Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar (in some sense or another) to each other than to those in other groups (clusters).Generally speaking, clustering is a hard problem, so it is difficult to identify a provably optimal clustering.

$k$-means¶
In k-means clustering we are given a set of d-dimensional vectors and we want to identify k sets $S_i$ such that
$$\sum_{i=0}^k \sum_{x_j \in S_i} ||x_j - \mu_i||^2$$is minimized where $\mu_i$ is the mean of cluster $S_i$. That is, all points are close as possible to the 'center' of the cluster.
Limitations
- Classical $k$-means requires that we be able to take an average of our points - no arbitrary distance functions.
- Must provide $k$ as a parameter.
- Clustering results are very sensitive to $k$; poor choice of $k$, poor clustering results.
The general algorithm for $k$-means is as follows:
1: Choose the initial set of $k$ centroids. These are essentially pseudo-datapoints that will be updated over the course of the algorithm.
2: Assign all the actual data points to one of the centroids--whichever centroid they're closest to.
3: Recompute the centroids based on the cluster assignments found in step 2.
4: Repeat until the centroids don't change very much.
Visualizing $k$-means¶
https://www.naftaliharris.com/blog/visualizing-k-means-clustering/
$K$-means examples¶
First let's make a toy data set...
%matplotlib inline
import matplotlib.pylab as plt
import numpy as np
randpts1 = np.random.randn(100, 2) / (4, 1) #100 integer coordinates in the range [0:50],[0:50]
randpts2 = (np.random.randn(100, 2) + (1, 0)) / (1, 4)
plt.plot(randpts1[:, 0], randpts1[:, 1], 'o', randpts2[:, 0], randpts2[:, 1], 'o')
X = np.vstack((randpts1,randpts2))

import sklearn.cluster as cluster
kmeans = cluster.KMeans(n_clusters = 2)
kmeans.fit(X)
# Get the cluster assignments.
clusters = kmeans.labels_
# Get the centroids.
means = kmeans.cluster_centers_
The means are the cluster centers
plt.scatter(X[:, 0], X[:, 1], c = clusters)
plt.plot(means[:, 0], means[:, 1], '*', ms = 20);

Changing $k$¶
Let's look at what happens if we change from $k = 2$ to $k = 3$.
kmeans = cluster.KMeans(n_clusters = 3)
kmeans.fit(X)
clusters, means = kmeans.labels_, kmeans.cluster_centers_
plt.scatter(X[:, 0], X[:, 1], c = clusters)
plt.plot(means[:, 0], means[:, 1], '*', ms = 20);

And for $k = 4$
kmeans = cluster.KMeans(n_clusters = 4)
kmeans.fit(X)
clusters, means = kmeans.labels_, kmeans.cluster_centers_
plt.scatter(X[:, 0], X[:, 1], c = clusters)
plt.plot(means[:, 0], means[:, 1], '*', ms = 20);

Will K-means always find the same set of clusters?
- Yes
- No
- Depends
What sort of data would k-means have difficulty clustering?
- Expression data
- Dose-response data
- Protein structures
- Genes
Hierarchical clustering¶
Hierarchical clustering creates a heirarchy, where each cluster is formed from subclusters.

There are two kinds of hierarchical clustering: agglomerative and divisive.
- Agglomerative clustering builds the hierarchy from the bottom up: start with all data points as their own clusters, find the two clusters that are closest, combine them into a cluster, repeat.
- Divisive clustering is the opposite: start with all data points as part of a single huge cluster, find the groups that are most different, and split them into separate clusters. Repeat.
Which do you think is easier, in practice?
Agglomerative clustering¶
Agglomerative clustering requires there be a notion of distance between clusters of items, not just the items themselves.
On the other hand, all you need is a distance function. You do not need to be able to take an average, as with $k$-means.
Distance (Linkage) Methods¶

- average: $$d(u,v) = \sum_{ij}\frac{d(u_i,v_j)}{|u||v|}$$
- complete or farthest point: $$d(u,v) = \max(dist(u_i,v_j))$$
- single or nearest point: $$d(u,v) = \min(dist(u_i,v_j))$$
linkage¶
scipy.cluster.hierarchy.linkage creates a clustering hierarchy. It takes three parameters:
- y the data or a precalculated distance matrix
- method the linkage method (default single)
- metric the distance metric to use (default euclidean)
import scipy.cluster.hierarchy as hclust
linkage_matrix = hclust.linkage(X)
- An $(n - 1) \times 4$ matrix $Z$ is returned.
- At the $i^{th}$ iteration, clusters with indices
Z[i, 0]andZ[i, 1]are combined to form cluster $n + i$. - A cluster with an index less than $n$ corresponds to one of the $n$ original observations.
- The distance between clusters
Z[i, 0]andZ[i, 1]is given byZ[i, 2]. - The fourth value
Z[i, 3]represents the number of original observations in the newly formed cluster.
print(X.shape)
print(linkage_matrix)
print(linkage_matrix.shape)
Dendograms¶
hclust.dendrogram(linkage_matrix,p=4,truncate_mode='level');#show first 4 levels

fcluster: extracting clusters from a hierarchy¶
fcluster takes a linkage matrix and returns a cluster assignment. It takes a threshold value and a string specifying what method to use to form the cluster.
help(hclust.fcluster)
Flatten based on distance threshold¶
clusters = hclust.fcluster(linkage_matrix,0.3,'distance')
len(set(clusters))
plt.scatter(X[:, 0], X[:, 1], c = clusters)

Flatten based on number of clusters¶
clusters = hclust.fcluster(linkage_matrix,4,'maxclust')
len(set(clusters))
plt.scatter(X[:, 0], X[:, 1], c = clusters)

fclusterdata¶
fclusterdata does both linkage and fcluster in one step. Let's try out different linkage methods.
clusters = hclust.fclusterdata(X, 4, 'maxclust', method = 'complete')
plt.scatter(X[:, 0], X[:, 1], c = clusters)

clusters = hclust.fclusterdata(X, 4, 'maxclust', method = 'average')
plt.scatter(X[:, 0], X[:, 1], c = clusters)

You can even use a non-Euclidean metric.
clusters = hclust.fclusterdata(X, 4, 'maxclust', method = 'average', metric = 'cityblock')
plt.scatter(X[:, 0], X[:, 1], c = clusters)

leaves_list¶
A hierarchical cluster imposes an order on the leaves. You can retrieve this ordering from the linkage matrix with leaves_list
hclust.leaves_list(linkage_matrix)
Clustering expression data¶
- Download http://mscbio2025.csb.pitt.edu/files/Spellman.csv
- read the expression data into a numpy array
- cluster it with the default parameters
- retrieve the leaves
- reorder the orginal data according the the leaf order
- display the result as a heatmap
from matplotlib.pylab import cm
data = np.genfromtxt('Spellman.csv',skip_header=1,delimiter=',')[:,1:]
Z = hclust.linkage(data,method='complete')
leaves = hclust.leaves_list(Z)
ordered = data[leaves]
plt.matshow(ordered, aspect = 0.01, cmap=cm.seismic);
plt.colorbar()

Part 2: Machine Learning¶
What is machine learning?
Wikipedia:
Machine learning is a subfield of computer science that evolved from the study of pattern recognition and computational learning theory in artificial intelligence. Machine learning explores the study and construction of algorithms that can learn from and make predictions on data.Dr. David Koes, University of Pittsburgh:
Creating useful and/or predictive computational models from data.Machine Learning can be considered a subfield of Artificial Intelligence.
These algorithms can be seen as building blocks to make computers learn to behave more intelligently by somehow generalizing rather that just storing and retrieving data items like a database system would do.
Here's an overly simple example:
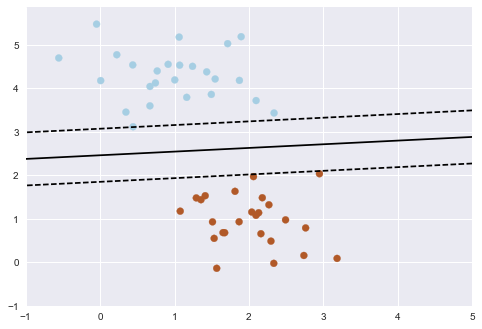
This may seem like a trivial task, but it is a simple version of a very important concept. By drawing this separating line, we have learned a model which can generalize to new data.
If you were to drop another point onto the plane which is unlabeled, this algorithm could now predict whether it's a blue or a red point.
scikit-learn¶
Scikit-Learn is a Python package designed to give access to well-known machine learning algorithms within Python code, through a clean, well-thought-out API. It has been built by hundreds of contributors from around the world, and is used across industry and academia.
Scikit-Learn is built upon Python's NumPy (Numerical Python) and SciPy (Scientific Python) libraries, which enable efficient in-core numerical and scientific computation within Python.
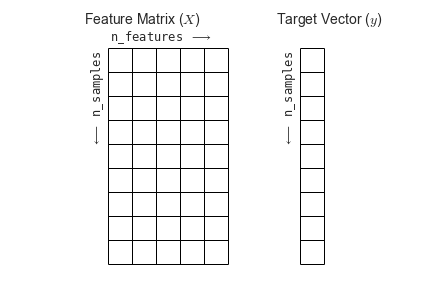
Representing Data¶
Machine learning is about creating models from data, and scikit-learn uses a particular layout for building its models.
Most machine learning algorithms implemented in scikit-learn expect data to be stored in a
two-dimensional array or matrix, typically as numpy arrays. The shape of the array is expected to be [n_samples, n_features]
Example: the Iris dataset¶
As an example of a simple dataset, we're going to take a look at the iris data (stored in scikit-learn, along with dozens of other sample datasets).
The data consists of measurements of three different species of irises.
There are three species of iris in the dataset, which we can picture here:
from IPython.core.display import Image, display
display(Image(filename = 'Lecture26/iris_setosa.jpg'))
print("Iris Setosa\n")
display(Image(filename = 'Lecture26/iris_versicolor.jpg'))
print("Iris Versicolor\n")
display(Image(filename = 'Lecture26/iris_virginica.jpg'))
print("Iris Virginica")



The iris data consists of the following:
Features in the Iris dataset:
- sepal length in cm
- sepal width in cm
- petal length in cm
- petal width in cm
Target classes to predict:
- Iris Setosa
- Iris Versicolour
- Iris Virginica
Accessing the iris data in scikit-learn is pretty easy:
from sklearn.datasets import load_iris
iris = load_iris()
We can examine this data more closely, using the properties of the various Python objects storing it:
iris.keys()
n_samples, n_features = iris.data.shape
print((n_samples, n_features))
print(iris.data[0])
print(iris.data.shape)
print(iris.target.shape)
print(iris.target)
print(iris.target_names)
This data is four dimensional, but we can visualize two of the dimensions at a time using a simple scatter-plot:
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
x_index = 0
y_index = 1
# this formatter will label the colorbar with the correct target names
formatter = plt.FuncFormatter(lambda i, *args: iris.target_names[int(i)])
plt.scatter(iris.data[:, x_index], iris.data[:, y_index],
c=iris.target, cmap=plt.cm.get_cmap('RdYlBu', 3))
plt.colorbar(ticks=[0, 1, 2], format=formatter)
plt.clim(-0.5, 2.5)
plt.xlabel(iris.feature_names[x_index])
plt.ylabel(iris.feature_names[y_index]);

Unsupervised Learning¶
Imagine we didn't have the target data (i.e., iris species) available, and wanted to cluster the data into similar groups.
In this case, we're discovering an underlying structure in the data without any a priori knowledge of categories or "ground truth". Hence, unsupervised.
Other forms of unsupervised learning include:
- dimensionality reduction, such as principal components analysis (PCA)
- expectation-maximization ($k$-means is a variant)
- self-organizing maps
- other clustering algorithms
Supervised learning¶
This is what we do in order to build models from data that DO include some form of "ground truth" labels.
The data consists of a set of examples X where each example has a label y.
Our assumption is that the label is a function of the data; our goal is to learn that function that maps X to y as accurately as possible: $y = f(X)$
Classification versus Regression¶
There are two types of supervised learning.
Classification maps an example to a discrete labels. This answers questions such as
- Will it rain tomorrow?
- Is the protein overexpressed?
- Do the cells die when a drug is added?
Regression maps an example to a continuous number. This answers questions such as
- How much rain will there be tomorrow?
- What is the expression level of the protein?
- What percent of the cells will die when the drug is added?
Flowchart for choosing your methods¶
This is a flow chart created by scikit-learn super-contributor Andreas Mueller which gives a nice summary of which algorithms to choose in various situations. Keep it around as a handy reference!
from IPython.display import Image
Image("http://scikit-learn.org/dev/_static/ml_map.png")

Back to iris¶
Given we have ground truth information (iris species), are we performing supervised or unsupervised learning on the iris data?
What if we didn't have grouth truth information? What kind of algorithms could we use?
What kind of supervised learning are we performing?
The iris data are 4-dimensional; can't exactly visualize that directly. We can, however, plot each pair of features in turn (this is called "getting a feel for the data").
import itertools
features = iris.data
feature_names = iris.feature_names
classes = iris.target
feature_combos = itertools.combinations([0, 1, 2, 3], 2)
for i, (x1, x2) in enumerate(feature_combos):
fig = plt.subplot(2, 3, i + 1)
fig.set_xticks([])
fig.set_yticks([])
for t, marker, c in zip(range(3), ">ox", "rgb"):
plt.scatter(features[classes == t, x1],
features[classes == t, x2],
marker = marker, c = c)
plt.xlabel(feature_names[x1])
plt.ylabel(feature_names[x2])

Features¶
The features, X, are what make each example distinct. Ideally they contain enough information to predict y. In the case of the iris dataset, the features have to do with petal and sepal measurements.
The pairwise feature plots give us some good intuition for the data. For example:
- The first plot, sepal width vs sepal length, gives us a really good separation of the Setosa (red triangles) from the other two, but a poor separation between Versicolor and Virginica
- In fact, this is a common theme across most of the subplots--we can easily pick two dimensions and get a good separation of Setosa from the others, but separating Versicolor and Virginica may be more difficult
- The best pairings for separating Versicolor and Virginica may be either petal length vs sepal width, or petal width vs sepal width.
Still, for any given pair of features, we can't get a perfect classification rule.
But that's ok!
K-nearest neighbors¶
Another algorithm with a $k$ in the name--this time, a supervised algorithm--is the simplest classifier you can design.
It asks, for any given data point $x$: What are the labels of the $k$ data points closest to $x$?
It then performs a majority vote, based on those labels. The winning label is assigned to the new data point $x$. The end!
Let's try it on the iris dataset.
from sklearn import neighbors
X, y = iris.data, iris.target
X = iris.data[:, :2] # For ease of interpretation
# create the model
knn = neighbors.KNeighborsClassifier(n_neighbors = 5)
# fit the model
knn.fit(X, y)
That's it. We've trained our classifier! Now let's try to predict a new, previously-unobserved iris:
# What kind of iris has 3cm x 5cm sepal?
# call the "predict" method:
result = knn.predict([[3, 5],])
print(iris.target_names[result])
Our completely-made-up new mystery iris is classified as a setosa!
We can visualize what this algorithm looks like:
from matplotlib.colors import ListedColormap
cmap_light = ListedColormap(['#FFAAAA', '#AAFFAA', '#AAAAFF'])
cmap_bold = ListedColormap(['#FF0000', '#00FF00', '#0000FF'])
### IGNORE THIS ###
x_min, x_max = X[:, 0].min() - .1, X[:, 0].max() + .1
y_min, y_max = X[:, 1].min() - .1, X[:, 1].max() + .1
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 100),
np.linspace(y_min, y_max, 100))
Z = knn.predict(np.c_[xx.ravel(), yy.ravel()])
# Put the result into a color plot
Z = Z.reshape(xx.shape)
plt.figure()
plt.pcolormesh(xx, yy, Z, cmap = cmap_light)
# Plot also the training points
plt.scatter(X[:, 0], X[:, 1], c = y, cmap = cmap_bold)
plt.xlabel('sepal length (cm)')
plt.ylabel('sepal width (cm)')
plt.axis('tight')

There are plenty of more sophisticated classifiers:
- support vector machines
- neural networks
- decision trees
- ...
Furthermore, you will often combine multiple methods into a machine learning pipeline. For example, rather than work directly with the 4D iris data, perhaps you'll run PCA on it first to reduce it to 2 dimensions, then classify it.
Machine learning is more of an art than a science; it takes a lot of "playing with the data" to find the right combination of model and pipeline that incorporates the right assumptions about the data and can generalize well.
scikit-learn makes it relatively easy to get started: you don't have to know how the algorithms are implemented underneath, but that knowledge does help in fine-tuning your pipelines.
Administrivia¶
- Assignment456 is out on JupyterHub! Due Wednesday, April 26 by 11:59:59pm.
- How are projects going? Lightning talks are Tuesday, April 25 (10-15 minutes with 5 minutes for questions).
- Project write-ups are due May 2 by 11:59:59pm.
- Last lecture of the semester on Thursday!
Additional Resources¶
- Richert, Willi and Pedro Coelho, Luis. Building Machine Learning Systems with Python. 2013. ISBN-13: 978-1782161400
- ACM Machine Learning Workshop https://github.com/eds-uga/acm-ml-workshop-2017/ (based on Jake VanderPlas' scikit-learn tutorial)